Thoughts and Theory
Achieving super-human performance in QWOP using Reinforcement Learning and Imitation Learning
The game is surprisingly difficult and shows the complexity of human locomotion.

Introduction
QWOP is a simple running game where the player controls a ragdoll’s lower body joints with 4 buttons. The game is surprisingly difficult and shows the complexity of human locomotion. Using machine learning techniques, I was able to train an AI bot to run like a human and achieve a finish time of 47 seconds, a new world record. This article walks through the general approach as well as the training process. Huge thanks to Kurodo (@cld_el), one of the world’s top speedrunners, for donating encoded game recordings to help train the agent.
Environment
The first step was to connect the QWOP to the AI agent so that it can interact with the game. To retrieve the game state, I wrote a Javascript adapter that extracted key variables from the game engine and made them accessible externally. Then Selenium was used to read game variables in Python and to send key presses to the browser.
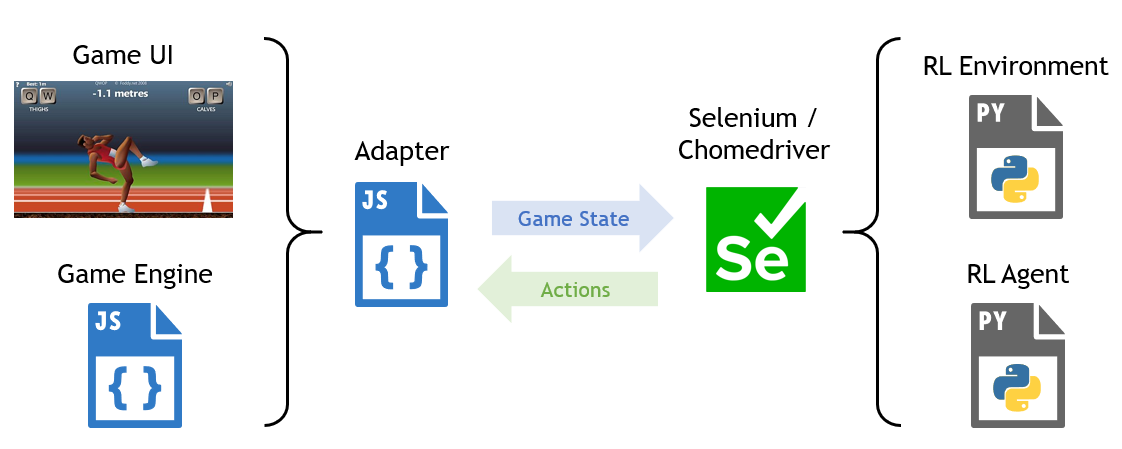
Next, the game was wrapped in an OpenAI gym style environment, which defined the state space, action space, and reward function. The state consisted of position, velocity and angle for each body part and joint. The action space consisted of 11 possible actions: each of the 4 QWOP buttons, 6 two-button combinations, and no keypress.
Approach
The first agent’s learning algorithm was Actor-Critic with Experience Replay (ACER)². This Reinforcement Learning algorithm combines Advantage Actor-Critic (A2C) with a replay buffer for both on-policy and off-policy learning. This means the agent not only learns from its most recent experience, but also from older experiences stored in memory. This allows ACER to be more sample efficient (i.e. learns faster) than its on-policy only counterparts.
To address the instability of off-policy estimators, it uses Retrace Q-value estimation, importance weight truncation, and efficient trust region policy optimization. Refer to the original paper² for more details.

ACER is fairly complex compared to most RL algorithms, so I used the Stable Baselines³ implementation instead of coding it myself. Stable Baselines also provided custom environment integration and pre-training capabilities which later proved to be very valuable.
The underlying Neural Network consisted of 2 hidden layers of 256 and 128 nodes, all fully connected with ReLU activations. The diagram below illustrates how the network ingests game states and produces candidate actions.

The full architecture is a bit more complex and contains more network outputs including a Q-value estimator.
In the second iteration of the agent, Prioritized DDQN⁷ was used to perfect the running technique and optimize for speed. This algorithm combines DQN with a number of features to stabilize and accelerate off-policy learning. This agent used the same network structure and activation function as the ACER one.

Training
Initial Trials
I first attempted to train the agent entirely through self-play. I was hoping the agent could learn to perform human locomotion similar to what DeepMind achieved in Mujoco environments⁴. However, after a number of trials, I noticed the only way it learned to finish the 100m was through “knee-scraping.” This was consistent with many previous attempts at solving QWOP with machine learning.

The agent simply wasn’t discovering the stride mechanic and instead learns the safest and slowest method to reach the finish line.
Learning to Stride
I then tried to teach the concept of strides to the agent myself. This is similar to the approach used by DeepMind for the original AlphaGo⁴, where the agent was first trained to mimic top players before self-play. However, I didn’t know any top players at the time so I tried to learn the game myself. Unfortunately, I’m quite terrible at the game and after a day of practice, I could only run about 28 meters.
Although I played poorly, I was still using legs in a way that a human would. I thought maybe the agent can pick up some signals from that mechanic. So I recorded and encoded 50 episodes of my mediocre play and fed it to the agent. Not surprisingly, the result was quite poor — the agent understood the idea of a stride but had no idea how to apply it.

I then let the agent train by itself to see if it could make use of the new technique. To my surprise, it actually learned to take strides and run like a human! After 90 hours of self-training, it was able to run a decent pace and complete the race in 1m 25s, which is a top 15 speedrun but still far from the top.

The agent wasn’t discovering a special technique used by all of the top speed runners: swinging the legs upwards and forwards to create extra momentum. I wanted to show the AI this technique but I was definitely not skilled enough to demonstrate it myself, so I reached out for help.
Learning Advanced Techniques
Kurodo (@cld_el), one of the world’s top QWOP speedrunners, was generous enough to record and encode 50 episodes of his play for my agent to learn from. I first tried supervised pre-training like before but the results were not great. The agent could not make use of the data immediately, and then quickly forgets/overwrites the pre-training experience.
I then tried injecting the experience directly into the ACER replay buffer for off-policy learning. Half of the agent’s memory would be games it played and the other half would be Kurodo’s experiences. This approach is somewhat similar to Deep Q-learning from Demonstrations (DQfD)⁶ except we don’t add all the demonstrations at the start, we add demonstrations at the same rate as real experience. The behavior policy µ(·|s) must also be included with each injection. Although there is little theoretical basis for this scheme, it worked surprisingly well.

However, the agent’s policy (actions) would become unstable after a while because it was unable to fully reconcile the external data with its own policy. At which point I removed the expert data from its memory and let it continue training by itself. The final agent had the following training schedule: pre-training, 25 hours by itself, 15 hours with Kurodo’s data, and another 25 hours by itself. The best recorded run of this agent was 1m 8s, which is a top 10 speedrun.
Optimizing for speed
Now that the agent mastered the correct techniques, I created a new agent solely for the purpose of improving speed. I recorded runs of the ACER agent and fed it to a new Prioritized DDQN⁷ agent. This DQN variant was chosen because it’s much more sample efficient so it can quickly optimize the techniques already learned by ACER.
The reward function was also modified. Previously it had a number of penalties including penalties for low torso height, vertical torso movement, and excessive knee bending. When the agent was just learning to stride, these helped stabilize its running technique. But now that it knows how to stride, I took the training wheels off and let it optimize purely for forward velocity.
The effective frame-rate for both training and testing were increased to 18 and 25 (from 9 previously) so that the agent could make more precise actions. The new agent was first pre-trained with ACER’s runs and then improved through self-learning. It did not do mixed memory training with Kurodo’s data like ACER did. It was trained for a total of 40 hours, of which all of it was self-learning except for a couple of minutes of pre-training.
Results
The best recorded run of the final agent was 47.34 seconds(below) which is faster than the best recorded run by a human (48.34 seconds). With this, QWOP is added to the list of games where AI has surpassed humans.
Links
- 1st Agent Video Summary: https://youtu.be/-0WQnwNFqJM
- 2nd Agent Video Summary: https://youtu.be/82sTpO_EpEc
- Github Repository: https://github.com/Wesleyliao/QWOP-RL
Article updated on 3/6/21 with new DQN model and world record run.
References
- QWOP (Foddy, 2008)
http://www.foddy.net/Athletics.html - Sample Efficient Actor-Critic with Experience Replay (Wang et al., 2017)
https://arxiv.org/pdf/1611.01224.pdf - Stable baselines (Hill, et al., 2018)
https://github.com/hill-a/stable-baselines - Emergence of Locomotion Behaviours in Rich Environments (Heess et al., 2017)
https://arxiv.org/pdf/1707.02286.pdf - Mastering the game of Go with deep neural networks and tree search (Silver et al., 2016)
https://doi.org/10.1038/nature16961 - Deep Q-learning from Demonstrations (Hester et al., 2017)
https://arxiv.org/pdf/1704.03732.pdf - Prioritized Experience Replay
https://arxiv.org/pdf/1511.05952.pdf

